- ALL COMPUTER, ELECTRONICS AND MECHANICAL COURSES AVAILABLE…. PROJECT GUIDANCE SINCE 2004. FOR FURTHER DETAILS CALL 9443117328
Projects > ELECTRONICS > 2017 > IEEE > DIGITAL IMAGE PROCESSING
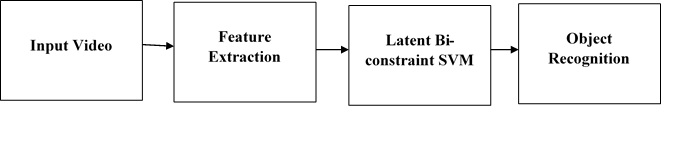
We address the task of recognizing objects from video input. This important problem is relatively unexplored, compared with image-based object recognition. To this end, we make the following contributions. First, we introduce two comprehensive datasets for video-based object recognition. Second, we propose Latent Bi-constraint SVM (LBSVM), a maximum margin framework for video-based object recognition. LBSVM is based on Structured-Output SVM, but extends it to handle noisy video data and ensure consistency of the output decision throughout time. We apply LBSVM to recognize office objects and museum sculptures, and we demonstrate its benefits over image-based, set-based, and other video-based object recognition.
Nearest-Neighbor Based Image Classification, Hidden Markov Models, Convolutional Neural Networks.
In this paper, we propose Latent Bi-constraint SVM (LBSVM), a novel algorithm for video-based object recognition. LBSVM is built on Structured-Output SVM (SOSVM), but extends it to address the challenges of recognizing objects from video input. LBSVM introduces two novel constraints and a latent variable. Its technical novelty is threefold: 1) The first constraint expands the training video, associates the object label to all subsequences of each training video. This enforces all subsequences of training video to be correctly classified, enabling the recognition of an object from various viewpoints. It also maximizes the usage of training data, reducing the need for a large number of training videos. 2) The second constraint requires the monotonicity of the score function with respect to the inclusion relationship between subsequences of a video. This is to ensure the consistency of the recognition decisions. 3) The incorporation of the latent variable allows the monotonicity requirement to be satisfied, discarding bad views of an object due to such factors as occlusion and motion blur. The two constraints and the latent variable allow LBSVM to ground the recognition decision on the entire video, avoiding the inconsistency of the output decisions.
BLOCK DIAGRAM