- ALL COMPUTER, ELECTRONICS AND MECHANICAL COURSES AVAILABLE…. PROJECT GUIDANCE SINCE 2004. FOR FURTHER DETAILS CALL 9443117328
Projects > ELECTRONICS > 2017 > IEEE > DIGITAL SIGNAL PROCESSING
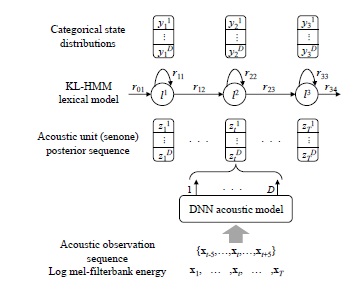
This paper addresses the problem of recognizing the speech uttered by patients with dysarthria, which is a motor speech disorder impeding the physical production of speech. Patients with dysarthria have articulatory limitation, and therefore, they often have trouble in pronouncing certain sounds, resulting in undesirable phonetic variation. Modern automatic speech recognition systems designed for regular speakers are ineffective for dysarthric sufferers due to the phonetic variation. To capture the phonetic variation, Kullback-Leibler divergence based hidden Markov model (KL-HMM) is adopted, where the emission probability of state is parametrized by a categorical distribution using phoneme posterior probabilities obtained from a deep neural network-based acoustic model. To further reflect speaker-specific phonetic variation patterns, a speaker adaptation method based on a combination of L2 regularization and confusion-reducing regularization which can enhance discriminability between categorical distributions of KL-HMM states while preserving speaker-specific information is proposed.
Fast Fourier Transform, SVM.
This paper addresses the problem of automatic recognition of dysarthric speech, focusing on implicit phonetic variation modeling. The contributions of the paper include the following: An effective application of Kullback-Leibler divergence-based HMM (KL-HMM) to dysarthric speech recognition for dealing with phonetic variation. KL-HMM is an emerging method as it offers a powerful and flexible framework for achieving implicit phonetic variation modeling. KL-HMM is a particular form of HMM in which the emission probability of state is parameterized by a categorical distribution of phoneme classes referred to as acoustic units. The categorical distribution is usually trained using phoneme posterior probabilities. In other words, a KL-HMM framework can be regarded as a combination of an acoustic model to obtain phoneme posterior probabilities from acoustic feature observations and a categorical distribution-based lexical model. Since HMM states are generally represented as subword lexical units in the lexicon, KL-HMM can model the phonetic variation against target phonemes. KL-HMM has been successfully utilized in various speech recognition applications such as non-native speech recognition and multilingual speech recognition. Therefore, the KL-HMM is expected to effectively capture the phonetic variation of dysarthric speech. This adaptation method can also be applied to train a DA initial model to make the system better fitted to general dysarthric speech. Therefore, we believe that the proposed adaptation method can effectively represent speaker-specific phonetic variation patterns, which can help in improving recognition performance.
KL-HMM framework