- ALL COMPUTER, ELECTRONICS AND MECHANICAL COURSES AVAILABLE…. PROJECT GUIDANCE SINCE 2004. FOR FURTHER DETAILS CALL 9443117328
Projects > ELECTRONICS > 2018 > IEEE > DIGITAL IMAGE PROCESSING
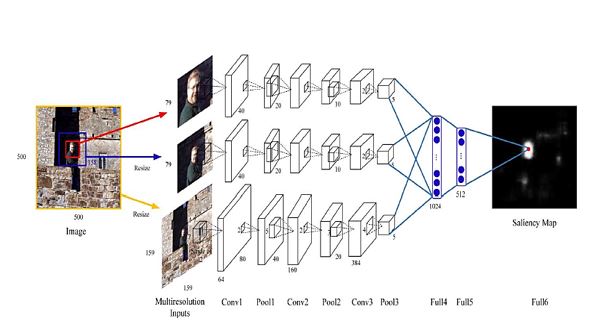
Eye movements in the case of freely viewing natural scenes are believed to be guided by local contrast, global contrast, and top-down visual factors. Although a lot of previous works have explored these three saliency cues for several years, there still exists much room for improvement on how to model them and integrate them effectively. This paper proposes a novel computation model to predict eye fixations, which adopts a multiresolution convolutional neural network (Mr-CNN) to infer these three types of saliency cues from raw image data simultaneously. The proposed Mr-CNN is trained directly from fixation and non-fixation pixels with multiresolution input image regions with different contexts. It utilizes image pixels as inputs and eye fixation points as labels. Then, both the local and global contrasts are learned by fusing information in multiple contexts. Meanwhile, various top-down factors are learned in higher layers. Finally, optimal combination of top-down factors and bottom-up contrasts can be learned to predict eye fixations. The proposed approach significantly outperforms the state-of-the art methods on several publically available benchmark databases, demonstrating the superiority of Mr-CNN. We also apply our method to the RGB-D image saliency detection problem. Through learning saliency cues induced by depth and RGB information on pixel level jointly and their interactions, our model achieves better performance on predicting eye fixations in RGB-D images.
Support Vector Machine (SVM)
By adopting the proposed Mr-CNN in eye fixation prediction problem, we simultaneously learn early features, local contrast, global contrast, top-down factors, and their integration intrinsically, rather than depending on hand-crafted features, computing mechanisms, and heuristic integration schemes. 2) We visualize hierarchical features learned from the Mr-CNN. The showed various features demonstrate that our Mr-CNN can learn both low-level features related to bottom-up saliency and high-level top-down factors. 3) The proposed method is evaluated on seven eye-tracking benchmark data sets and outperforms other ten state-of-the- art models by a large margin. 4) We apply our method to the RGB-D image saliency detection problem. Through automatically and jointly learning saliency cues from the RGB information and the depth information, the proposed method achieves better results compared with previous works.
BLOCK DIAGRAM