- ALL COMPUTER, ELECTRONICS AND MECHANICAL COURSES AVAILABLE…. PROJECT GUIDANCE SINCE 2004. FOR FURTHER DETAILS CALL 9443117328
Projects > ELECTRONICS > 2020 > IEEE > DIGITAL IMAGE PROCESSING
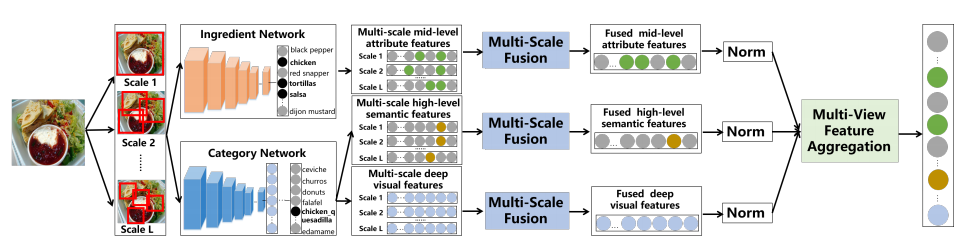
Recently, food recognition has received more and more attention in image processing and computer vision for its great potential applications in human health. Most of existing methods directly extracted deep visual features via Convolutional Neural Networks (CNNs) for food recognition. Such methods ignore characteristics of food images and are thus hard to achieve optimal recognition performance. In contrast to general object recognition, food images typically do not exhibit distinctive spatial arrangement and common semantic patterns. In this paper, we propose a Multi-Scale Multi-View Feature Aggregation (MSMVFA) scheme for food recognition. MSMVFA can aggregate high-level semantic features, mid-level attribute features and deep visual features into a unified representation. These three types of features describe the food image from different granularity. Therefore, the aggregated features can capture the semantics of food images with the greatest probability. For that solution, we utilize additional ingredient knowledge to obtain mid-level attribute representation via ingredient-supervised CNNs. High-level semantic features and deep visual features are extracted from class-supervised CNNs. Considering food images do not exhibit distinctive spatial layout in many cases, MSMVFA fuses multi-scale CNN activations for each type of features to make aggregated features more discriminative and invariable to geometrical deformation. Finally, the aggregated features are more robust, comprehensive and discriminative via the twolevel fusion, namely multi-scale fusion for each type of features and multi-view aggregation for different types of features. In addition, MSMVFA is general and different deep networks can be easily applied into this scheme. Extensive experiments and evaluations demonstrate that our method achieves state-of-the art recognition performance on three popular large-scale food benchmark datasets in Top-1 recognition accuracy. Furthermore, we expect this work will further the agenda of food recognition in the community of image processing and computer vision.
Multi-Scale Visual Recognition
In this paper, proposed a Multi-Scale Multi-View Feature Aggregation (MSMVFA) scheme for food recognition, where multiview means different types of feature sets. Different types of features with different granularity are jointly utilized in MSMVFA. Particularly, MSMVFA consists of two-level fusion, namely multi-scale fusion for each type of features and multi-view aggregation for different types of features. Considering food typically does not exhibit distinctive spatial arrangement, we utilize multi-scale fusion methods for each type of features. The coarsest scale is the whole image, so the global spatial layout is preserved, and the finer scales allow us to capture more local, fine-grained details of the food image. Therefore, such fused features are more robust and invariable to the geometrical deformation. Based on multiscale representation for each type of features, MSMVFA can further aggregate high-level semantic features, mid-level attribute features and deep visual features into a unified representation. These three types of features describe food images from different granularity. Therefore, the aggregated features can capture semantic information with the greatest probability. For that solution, we utilize additional ingredient information to fine-tune the deep network to extract midlevel attribute features. The high-level semantic features and deep visual features are extracted from class-supervised deep neural network. The resulting representation is more robust, comprehensive and discriminative as generic features for food recognition.
BLOCK DIAGRAM