- ALL COMPUTER, ELECTRONICS AND MECHANICAL COURSES AVAILABLE…. PROJECT GUIDANCE SINCE 2004. FOR FURTHER DETAILS CALL 9443117328
Projects > ELECTRONICS > 2017 > IEEE > VLSI
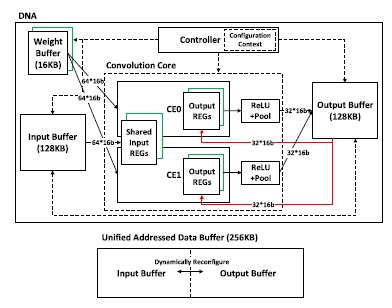
Deep convolutional neural networks (DCNNs) have been successfully used in many computer vision tasks. Previous works on DCNN acceleration usually use a fixed computation pattern for diverse DCNN models, leading to imbalance between power efficiency and performance. We solve this problem by designing a DCNN acceleration architecture called deep neural architecture (DNA), with reconfigurable computation patterns for different models. The computation pattern comprises a data reuse pattern and a convolution mapping method. For massive and different layer sizes, DNA reconfigures its data paths to support a hybrid data reuse pattern, which reduces total energy consumption by 5.9∼8.4 times over conventional methods. For various convolution parameters, DNA reconfigures its computing resources to support a highly scalable convolution mapping method, which obtains 93% computing resource utilization on modern DCNNs. Finally, a layer-based scheduling framework is proposed to balance DNA’s power efficiency and performance for different DCNNs.
Deep Residual Learning, Digital Neuromorphic Architecture.
A DCNN accelerating architecture proposed here should have reconfigurability for different networks and consider optimizations for both power efficiency and performance. To realize this goal, we design a reconfigurable architecture called deep neural architecture (DNA), with reconfigurable computation patterns for different DCNNs. This paper outperforms the previous works for three reasons. DNA can reconfigure its data paths to support a hybrid data reuse pattern for different layer sizes, instead of the fixed styles. DNA can reconfigure its computing resources to support a highly scalable and efficient mapping method, thus improving resource utilization for different convolution parameters. A layer-based scheduling framework is proposed to reconfigure DNA’s resources with optimization on both power efficiency and performance. In this paper, we start from algorithm-level optimizations for DCNNs, and then implement a reconfigurable architecture to support the optimized computation pattern for each layer.
BLOCK DIAGRAM