- ALL COMPUTER, ELECTRONICS AND MECHANICAL COURSES AVAILABLE…. PROJECT GUIDANCE SINCE 2004. FOR FURTHER DETAILS CALL 9443117328
Projects > ELECTRONICS > 2019 > IEEE > DIGITAL IMAGE PROCESSING
With advanced image journaling tools, one can easily alter the semantic meaning of an image by exploiting certain manipulation techniques such as copy-clone, object splicing, and removal, which mislead the viewers. In contrast, the identification of these manipulations becomes a very challenging task as manipulated regions are not visually apparent. This paper proposes a high-confidence manipulation localization architecture which utilizes resampling features, Long-Short Term Memory (LSTM) cells, and encoder-decoder network to segment out manipulated regions from non-manipulated ones. Resampling features are used to capture artifacts like JPEG quality loss, upsampling, downsampling, rotation, and shearing. The proposed network exploits larger receptive fields (spatial maps) and frequency domain correlation to analyze the discriminative characteristics between manipulated and non-manipulated regions by incorporating encoder and LSTM network. Finally, decoder network learns the mapping from low-resolution feature maps to pixel-wise predictions for image tamper localization. With predicted mask provided by final layer (softmax) of the proposed architecture, end-to-end training is performed to learn the network parameters through back-propagation using ground-truth masks. Furthermore, a large image splicing dataset is introduced to guide the training process. The proposed method is capable of localizing image manipulations at pixel level with high precision, which is demonstrated through rigorous experimentation on three diverse datasets.
Stacked auto-encoders (SAE).
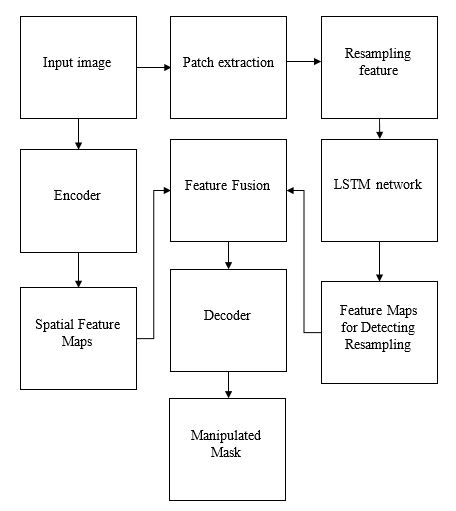
In this proposed system, we present a novel architecture to localize manipulated regions at pixel level for content-changing manipulation. Towards the goal of localizing manipulated regions in an image, we present a unified architecture that exploits resampling features, LSTM network, and encoder-decoder architectures in order to learn the pixel level localization of manipulated image regions. Given an image, we divide into several blocks/patches and then resampling features are extracted from each block. LSTM network is utilized to learn the correlation between manipulated and non-manipulated blocks at frequency domain. We utilize and modify encoder-decoder network as presented in to capture spatial information. Each encoder generates feature maps with varying size and number. The feature maps from LSTM network and the encoded feature maps from encoders are embedded before going through the decoder. We perform end-to-end training to learn the parameters of the network through back-propagation using ground-truth mask information. As deep networks are data hungry, a large number of images are synthesized to augment the training data.
BLOCK DIAGRAM