- ALL COMPUTER, ELECTRONICS AND MECHANICAL COURSES AVAILABLE…. PROJECT GUIDANCE SINCE 2004. FOR FURTHER DETAILS CALL 9443117328
Projects > ELECTRONICS > 2019 > IEEE > DIGITAL IMAGE PROCESSING
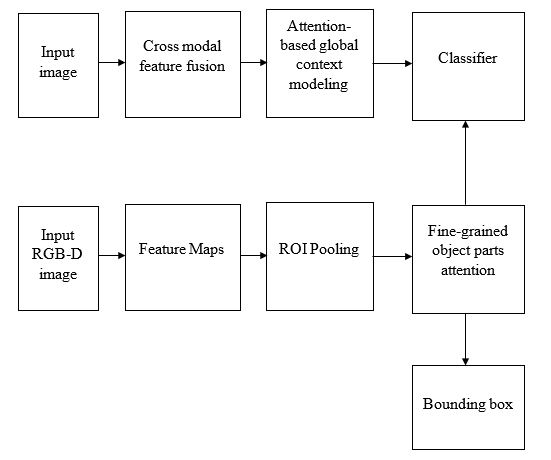
Recognizing objects from simultaneously sensed photometric (RGB) and depth channels is a fundamental yet practical problem in many machine vision applications such as robot grasping and autonomous driving. In this paper, we address this problem by developing a Cross-Modal Attentional Context (CMAC) learning framework, which enables the full exploitation of the context information from both RGB and depth data. Compared to existing RGB-D object detection frameworks, our approach has several appealing properties. First, it consists of an attention-based global context model for exploiting adaptive contextual information and incorporating this information into a region-based CNN (e.g., Fast RCNN) framework to achieve improved object detection performance. Second, our CMAC framework further contains a fine-grained object part attention module to harness multiple discriminative object parts inside each possible object region for superior local feature representation. While greatly improving the accuracy of RGB-D object detection, the effective cross-modal information fusion as well as attentional context modeling in our proposed model provide an interpretable visualization scheme. Experimental results demonstrate that the proposed method significantly improves upon the state of the art on all public benchmarks.
Context Information in Object Detection, Recurrent Attention Models
We propose a novel Cross Modal Attentional Context (CMAC) deep learning framework that effectively incorporates the correlated information between different modalities and successfully identifies useful contextual information both locally and globally for RGB-D object detection. An attention based global context module, based on an LSTM network, is utilized to recurrently generate contextual information from a global view for each object proposal. Multiple spatial transform networks are adopted in parallel to localize discriminative object parts for accurate object recognition.
BLOCK DIAGRAM