- ALL COMPUTER, ELECTRONICS AND MECHANICAL COURSES AVAILABLE…. PROJECT GUIDANCE SINCE 2004. FOR FURTHER DETAILS CALL 9443117328
Projects > ELECTRONICS > 2019 > IEEE > DIGITAL IMAGE PROCESSING
3D mask spoofing attacks have been one of the main challenges in face recognition. Compared to a 3D mask, a real face displays different facial motion patterns that are reflected by different facial dynamic textures. However, a large portion of these facial motion differences are subtle. We find that the subtle facial motion can be fully captured by multiple deep dynamic textures from a convolutional layer of a convolutional neural network, but not all deep dynamic textures from different spatial regions and different channels of a convolutional layer are useful for differentiation of subtle motions between real faces and 3D masks. In this paper, we propose a novel feature learning model to learn discriminative deep dynamic textures for 3D mask face antispoofing. A novel joint discriminative learning strategy is further incorporated in the learning model to jointly learn the spatialand channel-discriminability of the deep dynamic textures. The proposed joint discriminative learning strategy can be used to adaptively weight the discriminability of the learned feature from different spatial regions or channels, which ensures that more discriminative deep dynamic textures play more important roles in face/mask classification. Experiments on several publicly available datasets validate that the proposed method achieves promising results in intra- and cross-dataset scenarios.
Multi-Scale LBP, multi-spectrum analysis, CNN-RNN model
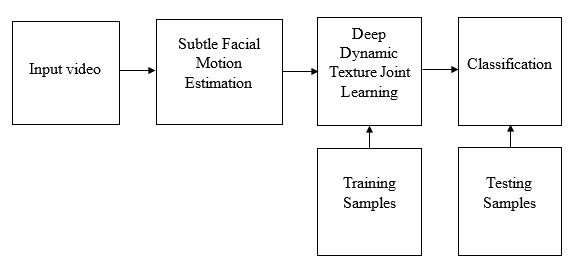
This proposed system presents an overview of the proposed method, which consists of three main blocks: 1) subtle facial motion estimation, 2) deep dynamic texture joint learning, and 3) classification. Given a preprocessed input video, all feature channels of a convolutional layer of every frame are first extracted using a pre-trained CNN. The subtle facial motions on each feature channel (of all frames) are then estimated using a motion estimation method such as optical flow, thus forming a preliminary feature set of multiple deep dynamic textures. The channel- and spatial-discriminability are then jointly learned with the preliminary feature sets of all training samples. The classification is eventually performed on the estimated feature sets with the learned channel- and spatial discriminability.
BLOCK DIAGRAM