- ALL COMPUTER, ELECTRONICS AND MECHANICAL COURSES AVAILABLE…. PROJECT GUIDANCE SINCE 2004. FOR FURTHER DETAILS CALL 9443117328
Projects > ELECTRONICS > 2020 > IEEE > DIGITAL IMAGE PROCESSING
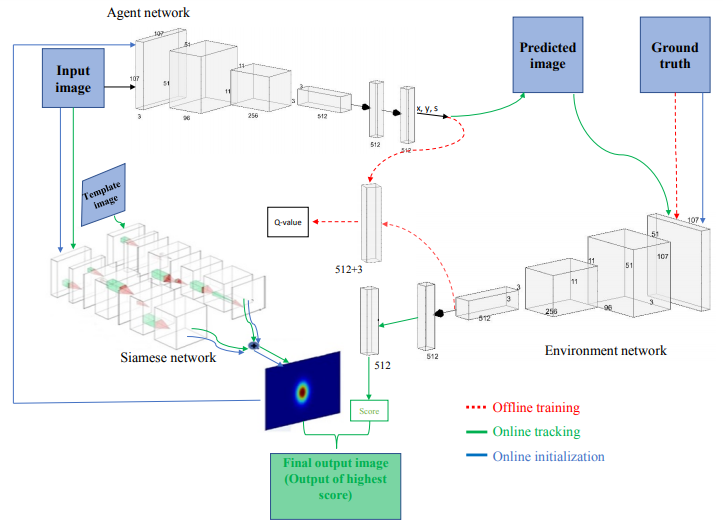
Balancing the trade-off between real-time performance and accuracy in object tracking is a major challenge. In this paper, a novel dynamic policy gradient Agent-Environment architecture with Siamese network (DP-Siam) is proposed to train the tracker to increase the accuracy and the expected average overlap while performing in real-time. DP-Siam is trained offline with reinforcement learning to produce a continuous action that predicts the optimal object location. DP-Siam has a novel architecture that consists of three networks: An Agent network to predict the optimal state (bounding box) of the object being tracked, an Environment network to get the Q-value during the offline training phase to minimize the error of the loss function, and a Siamese network to produce a heat-map. During online tracking, the Environment network acts as a verifier to the Agent network action.
Siamese-based Tracking, Reinforcement Learning-based Tracking
In this paper, we present a novel Siamese Agent- Environment architecture to achieve high accuracy (A) and Expected Average Overlap (EAO), by choosing the optimal state (bounding box) of the current object being tracked while performing in real time. Firstly, we propose DP-Siam, a novel dynamic Siamese Agent-Environment architecture that formulates the tracking problem with reinforcement learning. DP-Siam produces a continuous action that predicts the optimal object location. DP-Siam has a novel architecture that consists of three networks: An Agent network to predict the optimal state of the object being tracked, an Environment network to get the Q-value during the offline training phase to 80 minimize the error of the loss function, and a Siamese network to produce a heat-map. The Environment network acts as a verifier to the action of the Agent network during online tracking. Secondly, the proposed architecture allows the tracker to 85 dynamically select the hyper-parameters in each frame instead of the traditional method of fixing their values for the entire dataset, which to the best knowledge of the authors, has not been done before. Finally, the design of the proposed architecture increases the generalization.
BLOCK DIAGRAM