- ALL COMPUTER, ELECTRONICS AND MECHANICAL COURSES AVAILABLE…. PROJECT GUIDANCE SINCE 2004. FOR FURTHER DETAILS CALL 9443117328
Projects > ELECTRONICS > 2017 > IEEE > DIGITAL SIGNAL PROCESSING
Multichannel automatic speech recognition (ASR) systems commonly separate speech enhancement, including localization, beamforming, and post filtering, from acoustic modeling. In this paper, we perform multichannel enhancement jointly with acoustic modeling in a deep neural network framework. Inspired by beamforming, which leverages differences in the fine time structure of the signal at different microphones to filter energy arriving from different directions, we explore modeling the raw time-domain waveform directly. We introduce a neural network architecture, which performs multichannel filtering in the first layer of the network, and show that this network learns to be robust to varying target speaker direction of arrival, performing as well as a model that is given oracle knowledge of the true target speaker direction. Next, we show how performance can be improved by factoring the first layer to separate the multichannel spatial filtering operation from a single channel filter bank which computes a frequency decomposition. We also introduce an adaptive variant, which updates the spatial filter coefficients at each time frame based on the previous inputs. Finally, we demonstrate that these approaches can be implemented more efficiently in the frequency domain.
Deep Neural Networks, Recurrent Neural Network.
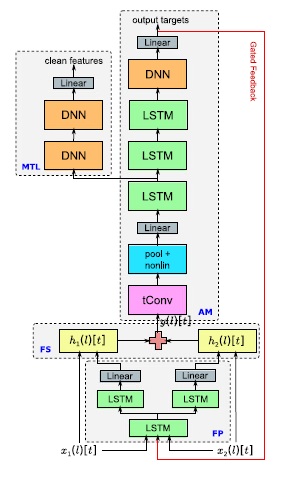
In this paper, we introduced a methodology to do multichannel enhancement and acoustic modeling jointly within a neural network framework. First, we developed a unfactored raw-waveform multichannel model, and showed that this model performed as well as a model given oracle knowledge of the true location. Next, we introduced a factored multichannel model to separate out spatial and spectral filtering operations, and found that this offered an improvement over the unfactored model. Next, we introduced an adaptive beamforming method, which we found to match the performance of the multichannel model with far fewer computations. Finally, we showed that we can match the performance of the raw-waveform factored model, with far fewer computations, with a frequency-domain factored model. In this paper we extend the idea of performing beamforming jointly with acoustic modeling, but do this within the context of a deep neural network (DNN) framework by training an acoustic model directly on the raw signal. DNNs are attractive because they have been shown to be able to perform feature extraction jointly with classification. The goal of this paper is to explore a variety of different joint enhancement/acoustic modeling DNN architectures that operate on multichannel signals. We will show that jointly optimizing both stages is more effective than techniques which cascade independently tuned enhancement algorithms with acoustic models. Since beamforming takes advantage of the fine time structure of the signal at different microphones, we begin by modeling the raw time-domain waveform directly. In this model, first layer consists of multiple time convolution filters, which map the multiple microphone signals down to a single time-frequency representation. As we will show, this layer learns bandpass filters which are spatially selective, often learning several filters with nearly identical frequency response, but with nulls steered toward different directions of arrival. The output of this spectral filtering layer is passed to an acoustic model, such as a convolutional long short-term memory, deep neural network (CLDNN) acoustic model. All layers of the network are trained jointly. Finally, since convolution between two-time domain signals is equivalent to the element-wise product of their frequency domain counterparts, we investigate speeding up the raw waveform neural network architectures described above by consuming the complex-valued fast Fourier transform of the raw input and implementing filters in the frequency domain.
Neural Network Adaptive Beamforming (NAB) Model Architecture